
AI Knowledge Distillation and Intellectual Property
Pine IP Firm
June 9, 2025
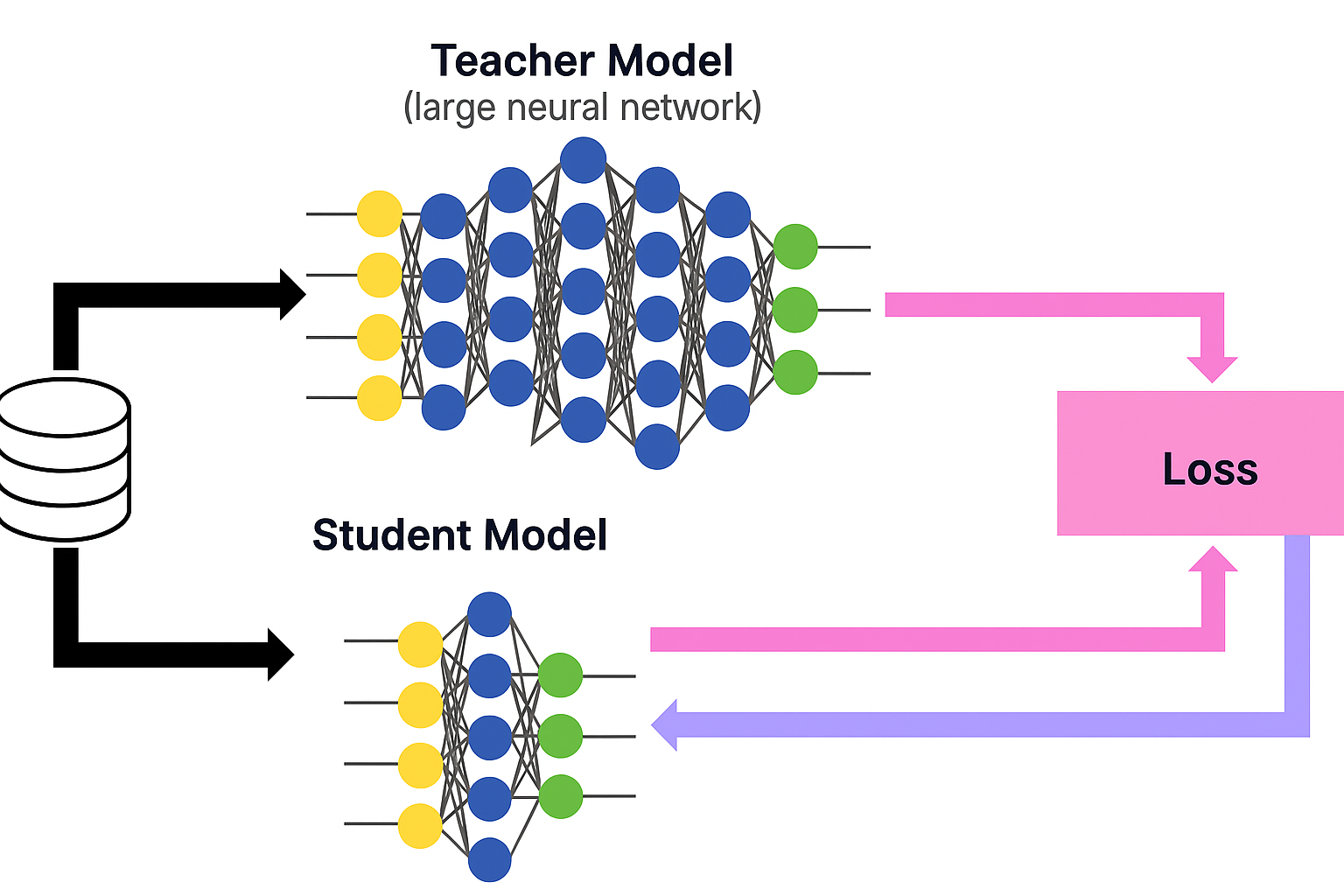
The global AI market—now at the summit of 21st-century technological competition—is in upheaval. Powerful challengers are emerging that achieve comparable performance to large, proprietary AI models at astonishingly low cost, a space once thought to be the exclusive domain of tech giants with astronomical capital and training time. These entrants are setting a new paradigm for AI advancement, jolting the industry and raising complex legal questions.
At the heart of this efficiency likely lies knowledge distillation. Much like a master imparting distilled know-how to a pupil, knowledge distillation transfers the “knowledge” of a pre-trained, large-scale AI model (the teacher) to a smaller, lighter model (the student).
Is it legitimate technological progress to train my AI by using another company’s model as the “teacher”? Or is it a subtle form of IP infringement that free-rides on another’s massive investment?
Before any legal analysis, a clear grasp of the technology is essential. Knowledge distillation is not simply copying an AI system.
Thanks to this technique, startups can develop high-performing AI at a fraction of the cost—sometimes in the mere millions of won—opening the door to the on-device AI era. The legal complication, however, is that most developers of teacher models (e.g., OpenAI, Google) explicitly prohibit using their model outputs to build competing models in their Terms of Service. That is where legal disputes may begin.
If unauthorized distillation triggers litigation, two bodies of law are likely to be central and contested: copyright law and the Unfair Competition Prevention Act. We analyze the issues step by step.
Key question: Can the teacher model’s outputs be regarded as “works” under copyright law so that training a student model on them constitutes infringement?
Legal analysis: Article 2(1) of Korea’s Copyright Act defines a “work” as a creative expression of human thought or emotion. The “human” element is decisive. Even if AI produces results from a user’s prompt, the final expression emerges from the AI’s autonomous computation. As seen in the U.S. Copyright Office’s decision regarding the AI-generated images in Zarya of the Dawn—recognizing human-authored text/arrangement while denying protection to AI-generated images—current legal frameworks do not treat AI as an author.
Conclusion: Teacher model outputs used in distillation are unlikely to qualify as human authorship. A copyright-infringement claim premised on those outputs, as the law stands, has a low likelihood of success.
Key question: If individual outputs lack protectable authorship, could the teacher’s vast set of answers be protected as a database, invoking the rights of a database producer?
Legal analysis: Copyright protection for databases requires that materials be systematically arranged or composed so that individual elements are accessible or searchable. In distillation, the teacher’s responses are typically generated on the fly for specific prompts—a stream of unstructured data rather than a pre-organized corpus maintained under a fixed schema. That is fundamentally different from a traditional, curated database.
Conclusion: Treating AI outputs used in distillation as a legal “database” faces substantial hurdles. Copyright law, as such, offers limited traction to regulate distillation.
Key question: Does knowledge distillation amount to the improper use of “data” under Subparagraph (ka) of Article 2(1) of the Unfair Competition Prevention Act?
Legal analysis: Subparagraph (ka) addresses the improper acquisition/use of technological or business information that is electronically accumulated and managed in substantial quantity. Given the real-time, ephemeral nature of AI outputs noted above, it is debatable whether such outputs meet the “substantial accumulation/management” requirement. Expect hard-fought disputes on this element.
Conclusion: Not impossible, but due to the “accumulated/managed” requirement, relying solely on this provision to curb distillation remains uncertain.
Key question: Is knowledge distillation an act of free-riding that exploits another’s substantial investment, thereby undermining fair competition?
Legal analysis: This is likely the main battleground. Subparagraph (pa) of Article 2(1) prohibits using, for one’s business, the results produced by another’s substantial investment or effort, in a manner contrary to fair commercial practices or order of competition, thereby infringing that party’s economic interests.
Conclusion: Even if copyright protection is tenuous, knowledge distillation may fit squarely within “free-riding on results” under the UCPA. If market leaders sue, this provision is a strong candidate to ground liability.
In this complex legal landscape, how should businesses survive and grow? Pine IP Firm recommends tailored strategies based on your position.
Knowledge distillation is undeniably powerful—poised to democratize AI and accelerate technology across industries. But its blade cuts both ways. If actors are permitted to exploit others’ massive investments without fair compensation in the name of “progress,” incentives to fund difficult, future-oriented R&D will collapse, harming the ecosystem itself.
The sustainable path is a transparent, fair licensing ecosystem. Market leaders should offer APIs and licensing programs on reasonable terms; late entrants should respect those rules and pay fair value. That virtuous cycle is how the industry advances.
Guided by Pine IP Firm.
