구글이 출원·등록한 「Attention-based decoder-only sequence transduction neural networks」 계열 특허군은, 오늘날 대형 언어 모델(LLM)의 사실상 표준 구조가 된 디코더-온리 트랜스포머의 핵심 골조를 정면으로 포착하고 있습니다.
특히 US 16/759,690을 기점으로 한 US 11,556,786 B2, US 11,886,998 B2, US 12,271,817 B2, US 12,299,572 B2, US 12,299,573 B2, US 12,354,005 B2 등 일련의 등록 특허들을 하나의 패밀리로 바라보면, 구글이 LLM의 어느 부분까지를 특허로 둘러쳤는가가 제법 선명하게 드러납니다.
1. 디코더-온리 특허의 공통 기술 사상
패밀리 전체를 관통하는 기술적 아이디어는 놀라울 만큼 단순합니다.
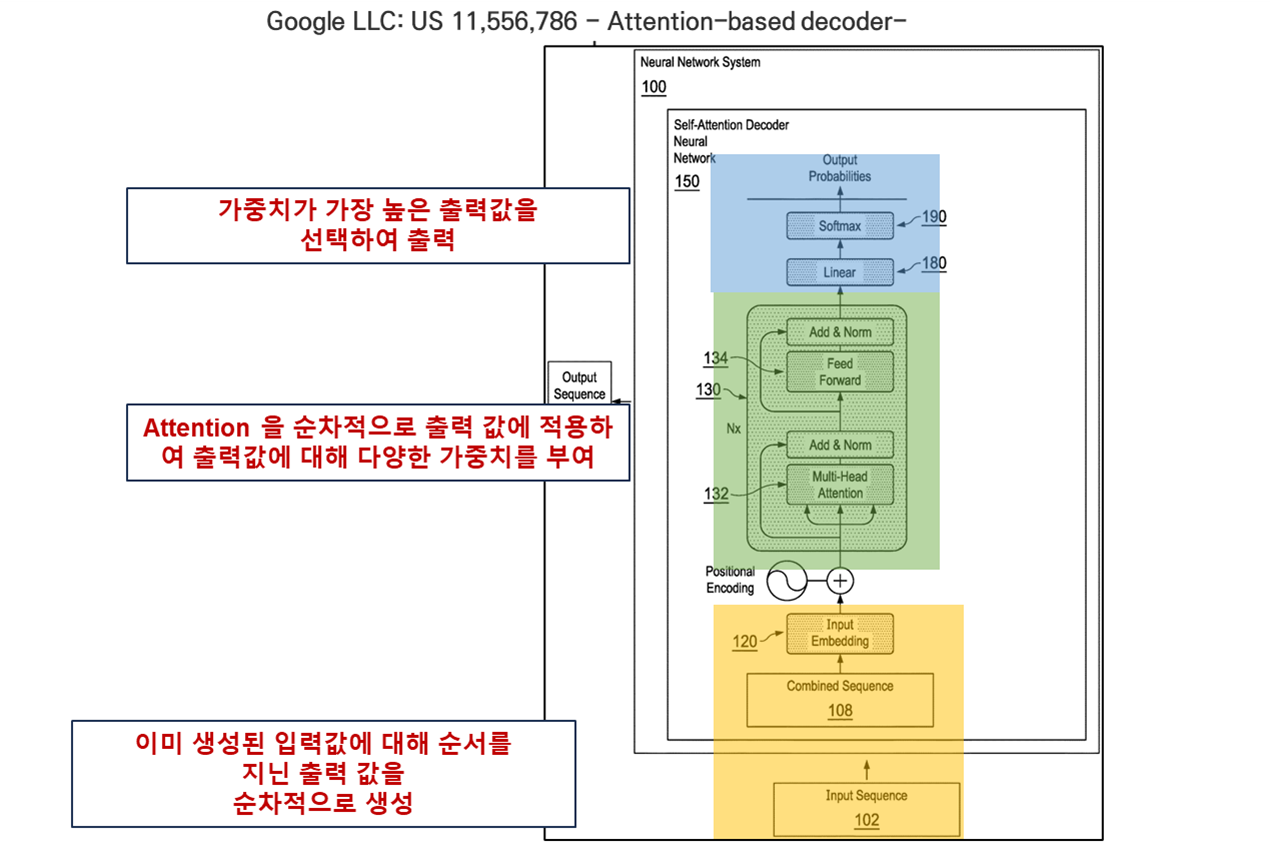
입력 시퀀스와 이미 생성된 출력 토큰들을 하나로 이어 붙인 결합 시퀀스(combined sequence)를 만들고, 이를 네트워크의 입력으로 사용합니다. 다시 말해, 특정 생성 시점에서의 입력은 입력 시퀀스 + 현재 시점까지 생성된 출력 시퀀스라는 하나의 긴 토큰열입니다.
이 결합 시퀀스를 자기-주의 기반 디코더 신경망(self-attention decoder neural network)에 통과시킵니다. 디코더는 여러 층의 마스크드 자기-주의 레이어(masked self-attention layers)로만 구성되며, 별도의 인코더는 존재하지 않습니다.
각 생성 시점에서의 네트워크 출력을 가능한 출력 토큰들에 대한 점수(확률) 분포로 해석하고, 이 분포에 기초해 다음 토큰을 선택합니다.
여기서 마스킹은 독립항에서 반복적으로 강조되는 핵심 요소입니다. 각 타임스텝의 출력은 입력 시퀀스와 이미 생성된 출력 토큰들만을 참조할 수 있고, 미래 토큰은 절대 볼 수 없습니다. 우리가 실무에서 흔히 이야기하는 오토리그레시브(autogressive) 디코더-온리 트랜스포머 구조를 특허용 언어로 정리한 것이 바로 이 부분입니다.
요약하면, 이 특허군은 입력·출력을 하나의 결합 시퀀스로 만들어 순수 디코더 구조에 집어넣고, 마스크드 self-attention만으로 토큰을 한 개씩 생성하는 방식을 중심축으로 권리범위를 구성하고 있습니다.
2. 기존 트랜스포머 특허와의 관계
대부분의 엔지니어가 알고 있는 2017년 논문 「Attention is All You Need」는 인코더-디코더 구조를 전제로, 양쪽에 멀티헤드 self-attention을 도입한 attention 기반 시퀀스 변환 모델을 제안합니다. 이에 대응하는 특허가 바로 「Attention-based sequence transduction neural networks」 패밀리로, 인코더와 디코더를 모두 포함하는 전형적인 구조를 포괄적으로 청구하고 있습니다.
반면 이번에 문제되는 「Attention-based decoder-only sequence transduction neural networks」 패밀리는, 동일한 우선권을 공유하면서 구조를 다음과 같이 재편합니다.
하나는 인코더를 완전히 제거하고 디코더만 남기는 것입니다. 다른 하나는 입력 시퀀스를 별도로 인코딩하는 대신, 입력과 과거 출력을 하나의 시퀀스로 합쳐 디코더에 넣는다는 점입니다.
결과적으로, 기존 패밀리가 attention 기반 인코더-디코더 전체 구조를 보호한다면, 디코더-온리 패밀리는 combined sequence를 사용하는 디코더-온리 구조라는 보다 최근 세대의 LLM 골조를 별도로 점유하고 있다고 볼 수 있습니다.
유럽에서는 이미 인코더-디코더 패밀리뿐 아니라 디코더-온리 패밀리 역시 EP 등록이 완료되어 있습니다. 한국에서도 국제출원(PCT)을 기점으로 대응출원이 진행되었기 때문에, 국내 FTO를 검토할 때 두 패밀리를 모두 평면 위에 올려 놓고 바라보는 것이 필요합니다.
3. US 16/759,690 계열의 구조
Google은 2017년 우선권을 기점으로, 동일 명세서를 여러 차례 continuation 형태로 분할해 각기 다른 포커스를 가진 특허를 다수 확보했습니다. 그 전체 그림을 간단히 정리하면 다음과 같습니다.
[1] US 11,556,786 B2 (기본 디코더-온리 구조)
Claim 1
A method of generating an output sequence comprising a plurality of output tokens from an input sequence comprising a plurality of input tokens,
the method comprising, at each of a plurality of generation time steps:
generating a combined sequence for the generation time step that includes the input sequence followed by the output tokens that have already been generated as of the generation time step;
processing the combined sequence using a self-attention decoder neural network, wherein the self-attention decoder neural network comprises a plurality of neural network layers that include a plurality of masked self-attention neural network layers,
and wherein the self-attention decoder neural network is configured to process the combined sequence through the plurality of neural network layers to generate a time step output that defines a score distribution over a set of possible output tokens; and
selecting, using the time step output, an output token from the set of possible output tokens as the next output token in the output sequence.
가장 먼저 등록된 US 11,556,786 B2는 디코더-온리 구조 자체를 비교적 넓게 포괄하는 기본형입니다. 입력과 출력 토큰의 종류에 큰 제한을 두지 않고, 결합 시퀀스, 마스크드 self-attention, 토큰 선택이라는 세 축을 중심으로 출력 시퀀스 생성 방법을 청구합니다.
[2] US 11,886,998 B2 (훈련 방법 / Training)
Claim 1
A computer-implemented method of training a self-attention decoder neural network for processing an input sequence comprising a plurality of input tokens to generate an output sequence comprising a plurality of output tokens,
wherein the self-attention decoder neural network comprises a plurality of neural network layers that include a plurality of masked self-attention neural network layers,
the method comprising, for each of a plurality of iterations:
obtaining one or more training examples, wherein each training example comprises a respective training input sequence and a respective training output sequence;
for each respective training example, processing, using the self-attention decoder neural network according to current values of parameters of the self-attention decoder neural network, a combined sequence comprising (i) tokens in the respective training input sequence and (ii) tokens in the respective training output sequence
to generate a respective prediction output that comprises a respective time step output for each of the tokens in the respective training output sequence; and
updating the current values of the parameters of the self-attention decoder neural network based on (i) the respective training output sequences and (ii) the respective prediction outputs.
이후 US 11,886,998 B2에서는 동일 구조에 대한 훈련 방법을 별도로 떼어냅니다. 각 훈련 예제마다 입력과 정답 출력 시퀀스를 이어 붙인 결합 시퀀스를 네트워크에 입력하고, 정답 출력 시퀀스의 각 위치에 대응하는 예측 분포를 얻어 파라미터를 업데이트하는, 이른바 teacher forcing 기반 학습 루프를 독립항 차원에서 정리한 것입니다. 모델 구조뿐 아니라 트레이닝 루프 자체가 별도의 권리범위가 되는 셈입니다.
[3] US 12,271,817 B2 (자연어 LLM 특화)
Claim 1
A method for generating an output sequence comprising a plurality of output tokens from an input sequence comprising a plurality of input tokens selected from a vocabulary that includes natural language tokens,
the method comprising, at each of a plurality of generation time steps:
generating a combined sequence for the generation time step that includes the input sequence followed by the output tokens that have already been generated as of the generation time step;
processing the combined sequence using a self-attention decoder neural network that comprises a plurality of masked self-attention neural network layers, and wherein the self-attention decoder neural network is configured to process the combined sequence to generate a time step output that defines a score distribution over a set of possible output tokens,
wherein the masked self-attention neural network layers are masked such that the time step output depends only on the input sequence and the output tokens that have already been generated as of the generation time step and not on any output tokens that are after the last token that had already been generated in the output sequence; and
determining an output token using the time step output.
US 12,271,817 B2에서는 입력 토큰이 포함된 어휘가 자연어 토큰을 포함하는 vocabulary임을 명시해, 자연어 LLM에 보다 직접 대응하는 형태로 범위를 조정합니다. 같은 기술사상을 유지하면서도, 실제 챗봇·텍스트 생성 서비스에 대한 적용 가능성을 더욱 선명히 하기 위한 선택으로 해석할 수 있습니다.
[4] US 12,299,572 B2 (Mixture-of-Experts 포함)
Claim 1
A method for generating an output sequence comprising a plurality of output tokens from an input sequence comprising a plurality of input tokens,
the method comprising, at each of a plurality of generation time steps:
generating a combined sequence for the generation time step that includes the input sequence followed by the output tokens that have already been generated as of the generation time step;
processing the combined sequence using a self-attention decoder neural network that comprises (i) one or more masked self-attention neural network layers and (ii) one or more mixture of expert layers to generate a time step output that defines a score distribution over a set of possible output tokens,
wherein the masked self-attention neural network layers are masked such that the time step output depends only on the input sequence and the output tokens that have already been generated as of the generation time step and not on any output tokens that are after the last token that had already been generated in the output sequence; and
determining an output token using the time step output.
US 12,299,572 B2는 디코더 내부에 Mixture-of-Experts(MoE) 레이어를 명시적으로 포함시킴으로써, 최근 대규모 모델에서 널리 쓰이는 MoE 스케일링 기법을 결합한 버전입니다. self-attention 레이어와 MoE 레이어를 함께 사용하는 디코더 구조를 구현한다면, 이 특허와의 충돌 가능성까지 따로 검토해야 합니다.
[5] US 12,299,573 B2 (이미지 생성 버전)
Claim 1
A method for processing an input sequence comprising a plurality of input tokens, the method comprising:
at each of a plurality of generation time steps:
generating a combined sequence for the generation time step that includes the input sequence followed by output tokens based on time step outputs that have already been generated as of the generation time step;
processing the combined sequence using a self-attention decoder neural network that comprises a plurality of masked self-attention neural network layers, and wherein the self-attention decoder neural network is configured to process the combined to generate a time step output,
wherein the masked self-attention neural network layers are masked such that the time step output depends only on the input sequence and the output tokens that have already been generated as of the generation time step and not on any output tokens that are after the last token that had already been generated; and
generating an output image using the time step outputs generated at the plurality of generation time steps.
US 12,299,573 B2는 동일 구조를 이미지 생성에 적용하는 시나리오를 정면으로 잡습니다. 출력 시퀀스를 단순 텍스트가 아니라 출력 이미지를 구성하기 위한 토큰열로 보면서, 복수의 생성 시점에서 얻어진 time step 출력들을 사용해 이미지를 생성하는 단계를 독립항의 결론부에 올려놓습니다. 텍스트-투-이미지, 비전-언어 모델 등 최신 서비스와의 접점이 생기는 지점입니다.
[6] US 12,354,005 B2 (시스템 / 플랫폼 청구)
Claim 1
A system comprising:
a user computer; and
a computer system comprising one or more computers and one or more storage devices storing instructions that when executed by the one or more computers cause the one or more computers to perform operations comprising:
receiving, from the user computer, input data specifying an input sequence comprising a plurality of input tokens of a natural language;
at each of a plurality of generation time steps:
generating a combined sequence for the generation time step that includes the input sequence followed by output tokens that have already been generated as of the generation time step;
processing the combined sequence using a self-attention decoder neural network that comprises a plurality of masked self-attention neural network layers, and wherein the self-attention decoder neural network is configured to process the combined sequence to generate a time step output; and
determining a respective output token using the time step output; and
providing, to the user computer, output data specifying an output sequence comprising the output tokens determined for the plurality of generation time steps.
US 12,354,005 B2는 사용자 컴퓨터와 서버 시스템 전체를 포괄하는 시스템/플랫폼 청구입니다. 사용자 단말로부터 자연어 입력 시퀀스를 전달받고, 서버 측에서 디코더-온리 네트워크가 동작해 출력 시퀀스를 생성한 뒤 다시 사용자 단말에 제공하는, 클라우드 기반 LLM 서비스 구조를 전형적으로 묘사합니다.
하나의 기술사상을 두고 구조, 훈련, 도메인 특화 응용, 플랫폼이라는 네 겹의 포트폴리오로 둘러싼 구조라고 이해하시면 됩니다.
4. 국내·국제 출원 상황과 실무적 의미
디코더-온리 패밀리는 PCT 국제출원을 거쳐 유럽, 중국, 한국 등 주요 관할권에 진입한 것으로 확인됩니다. 유럽에서는 이미 여러 건의 EP 특허가 등록되었고, 일부 출원은 비교적 최근까지도 심사·이의절차가 진행 중입니다. 한국에서도 대응 출원이 공고·심사된 바 있어, 향후 AI 관련 분쟁에서 선행·후행 양측 모두에서 자주 인용될 가능성이 큽니다.
한국 실무자는, 인코더-디코더 패밀리와 디코더-온리 패밀리를 하나의 베이스 라인으로 보고, 국내 클라이언트의 LLM 구조가 이 특허군과 어느 정도 겹치는지 먼저 claim chart 수준에서 대조해 보는 것이 필요합니다.
5. 한국 기업을 위한 FTO 및 회피설계 관점
실제 FTO를 검토할 때에는 몇 가지 축에서 구조를 비교하게 됩니다.
입력과 과거 출력이 단순 연결된 combined sequence인지, 아니면 별도 버퍼나 메모리 구조를 통해 분리된 형태로 처리하는지. 인코더 없이 디코더만으로 처리하는 구조인지, 아니면 별도의 프리프로세싱 인코더를 두고 있는지. 디코더 레이어 구성이 마스크드 self-attention과 일반 FFN으로만 이루어져 있는지, MoE나 기타 특수한 서브-네트워크를 사용하고 있는지. 훈련 루프에서 입력·출력 전체 시퀀스를 동시에 네트워크에 투입하는지, 부분 시퀀스에 대한 샘플링이나 다른 학습 전략을 사용하는지. 서비스 제공 방식이 온프레미스 설치형인지, 클라우드 API 기반인지 등입니다.
최근 대부분의 상용 LLM은 광범위하게 디코더-온리 구조를 채택하고 있기 때문에, 구조 자체만으로 완전히 자유로워지기는 쉽지 않습니다. 실무적으로는, 구조 자체를 정면으로 회피하기보다는 그 위에 올라가는 상위 레이어에서 차별화를 도모하는 전략이 현실적입니다.
예를 들어, 컨텍스트 확장을 위한 외부 메모리·검색(RAG), RLHF와 안전성 평가, 프롬프트 스케줄링, 멀티에이전트 오케스트레이션, 추론 최적화(캐싱, 샤딩, 메모리 관리) 등은 아직 상대적으로 특허 지형이 덜 포화된 영역입니다. 또한 동일한 디코더-온리 골조를 사용하더라도, 포지션 인코딩, 토큰 압축, 라우팅 전략, sparsity 제어와 같은 세부 기법을 발명 포인트로 잡는 것도 하나의 방향입니다.
훈련 방법 측면에서도, teacher forcing 기반의 전통적인 cross-entropy 학습을 넘어, 커리큘럼 러닝, 액티브 러닝, 도메인 적응 알고리즘 등에서 독립된 발명을 구성할 수 있습니다. 이 경우에는 Google의 훈련 방법 특허와 차별되는 loss 구성·데이터 샘플링 전략을 명확히 설계해 두는 것이 바람직합니다.
6. 우리 출원 전략에 주는 시사점
이 특허군은 단순히 구글이 잘 써 놓은 특허를 넘어, AI·LLM 관련 발명을 담당하는 한국 실무자에게 몇 가지 중요한 시그널을 줍니다.
첫째, 하나의 우선권을 기점으로 구조, 훈련, 응용, 시스템을 나누어 여러 건의 특허로 이어가는 continuation/divisional 전략의 위력입니다. 한국에서도 초기 명세서를 가능하면 넓고 풍부하게 작성해 두어야, 이후 분할출원이나 해외 우선권 주장 시에 다양한 청구 조합을 설계할 수 있습니다.
둘째, 모델 구조 그 자체뿐 아니라 훈련 과정과 서비스 제공 시스템까지 별도의 권리범위로 확보하는 전략입니다. 국내 출원에서도 가능한 경우, 방법–장치–기록매체 삼각구조에 더해 훈련 방법과 서비스 시스템(플랫폼)을 별도 독립항으로 설계해 둘 필요가 있습니다.
셋째, 실제 수익이 발생하는 응용 도메인에 특화된 청구항의 가치입니다. 자연어 LLM, 이미지 생성, 멀티모달 모델 등 구체적 사용처를 명시한 버전은, 침해 판단 단계에서 훨씬 직관적인 claim chart를 가능하게 해 줍니다.
7. 맺음말
정리하면, 구글의 디코더-온리 트랜스포머 특허 패밀리는 LLM 시대의 기본 골조를 상당 부분 선점한 상태에서, 구조·훈련·응용·시스템이라는 네 개의 층위로 입체적인 특허 장벽을 구축하고 있다고 볼 수 있습니다.
한국 변리사·변호사 입장에서 이 특허군은, 앞으로 AI·LLM 관련 사건을 다룰 때 피할 수 없는 기본 지도에 가깝습니다. 기술적 논의를 할 때 트랜스포머를 너무 쉽게 공공재처럼 취급하는 것은, 실제 특허 지형과는 상당한 괴리가 있습니다.
실제 의뢰 사건에서는, 의뢰인의 모델 구조와 훈련 파이프라인, 배포 방식까지 구체적으로 파악한 뒤, 이 특허군을 기준으로 세밀한 claim chart를 작성하고, 그 위에서 FTO·회피설계·출원 전략을 설계하는 접근이 필요할 것입니다.
파인특허법률사무소는 향후 관련 판례·유럽 opposition·미국 IPR 동향 등을 지속적으로 추적하면서, 국내 AI 기업이 글로벌 특허 지형 속에서 어떤 위치를 차지할 수 있을지, 보다 구체적인 전략을 제시해 나가고자 합니다.